

TL;DR
• In one 2025 CFO survey, 68% of CFOs said they lacked confidence in the consistency of their financial data. The data underneath their tools was never designed as a durable source of record.
• When revenue reporting depends on rep-entered CRM fields, finance rebuilds the numbers from manual reconciliations and undocumented judgment calls every reporting cycle.
• Finance needs revenue records written when a material signal arrives, with the source attached, that do not need to be rebuilt for each report.
• When revenue reporting depends on rep-entered CRM fields, finance rebuilds the numbers from manual reconciliations and undocumented judgment calls every reporting cycle.
• Finance needs revenue records written when a material signal arrives, with the source attached, that do not need to be rebuilt for each report.
The Data Problem Finance Already Knows About
The deal was supposed to close at $180K. It came in at $140K, or didn't close at all. The customer CS flagged as healthy churned two weeks later. The Q4 number sales committed to in October looked nothing like November actuals. Every CFO in a mid-market SaaS company has lived some version of this, usually more than once in a quarter.
The instinct is to blame the CRM. Incomplete fields, inconsistent stages, close dates that never move. But fixing the CRM misses the actual problem. Even if every rep filled in every field perfectly, you still couldn't trust the data. Because the person filling it in is paid on commission, managed on quota attainment, and has every professional incentive to believe their deal is closer than it is. A rep who marks a deal "commit" isn't lying. They're optimistic. Their manager who rolls it up into the forecast without pushback isn't lying either. They're protecting their number.
That's not a character flaw. It's how the incentive structure works. And it means that any revenue data that passed through a human who had a reason to shade it is, by definition, not objective.
A RevOps leader at a mid-market SaaS company described the audit ahead of a board roadmap presentation on user and usage data: contacts with no active owner, missing emails, and duplicate emails throughout. "52 percent of quote-unquote users," he said. "That field doesn't mean anything." A field driving board-level reporting on active users turned out to be a label no one had governed, validated, or traced to a source. The board presentation had to be rebuilt from scratch.
A 2025 CFO survey found that 68% of mid-market CFOs lack confidence in the consistency of their financial data. A separate 2025 CFO survey found that 52% of finance leaders cite improving data quality as a top priority for 2026. The common response is CRM hygiene: audit the fields, enforce validation rules, chase down the reps. That does not fix the objectivity problem. It applies rigor to data that was never objective in the first place.
What finance actually needs is what product and growth teams already have: an analytics layer that observes behavior directly rather than asking participants to self-report. A product analytics tag doesn't ask users to log their own activity. It watches what they do and records it. Revenue intelligence needs to work the same way. Observe every email, every call, every contract event, every support ticket, every product interaction. Record what happened, not what a rep thought happened. That is the only source of revenue data finance can actually trust.
What Finance-Ready Revenue Records Actually Require
CRM hygiene cleans labels, fills blanks, and removes duplicates. It does not make the underlying data objective. A rep who enters a clean, correctly formatted "commit" stage on a deal they have been hoping to close for three months has still entered a guess.
Objective data collection means the record is written from the signal itself, not from a rep's interpretation of it. When a prospect replies to an email saying the budget has been pushed to next quarter, that is a fact. The email exists. The date exists. The words exist. None of that requires a rep to decide how to categorize it or remember to log it. A system that reads the email and writes a timestamped risk flag to the opportunity record is creating objective data. A system that waits for the rep to update the stage is collecting an opinion.
For finance, every revenue record needs three things: the right field type, the source that produced it, and the timestamp. If those are missing, the number has to be rebuilt later, manually, by an analyst, using judgment that cannot be audited.
Finance needs currency fields for ARR, approved categories for pipeline stage, and date fields for close dates. Every value stores actor, timestamp, source object, and trigger. For example: "email thread #4471 set risk flag on 2026-06-13." When records store source, actor, timestamp, and review status, AI tools query approved opportunity fields instead of stale rep-entered notes.
Why AI Agents Can't Fix This
One 2025 analyst forecast projected that 60% of AI projects would be abandoned by 2026 because the underlying data was not ready. A human analyst queries bad data and applies judgment. An AI agent that reads that field will treat it as ground truth and can repeat the error in any forecast or report generated from the same record.
The appealing idea is to ask the AI to scan every email, every call transcript, every opportunity at query time. If the agent has to rescan hundreds of emails and call transcripts before each answer, finance waits on a fresh summary instead of reading an approved field. It also misses risks no one queried, like a budget objection buried in yesterday's thread, a champion who went quiet, or a deal that has not moved in 18 days.
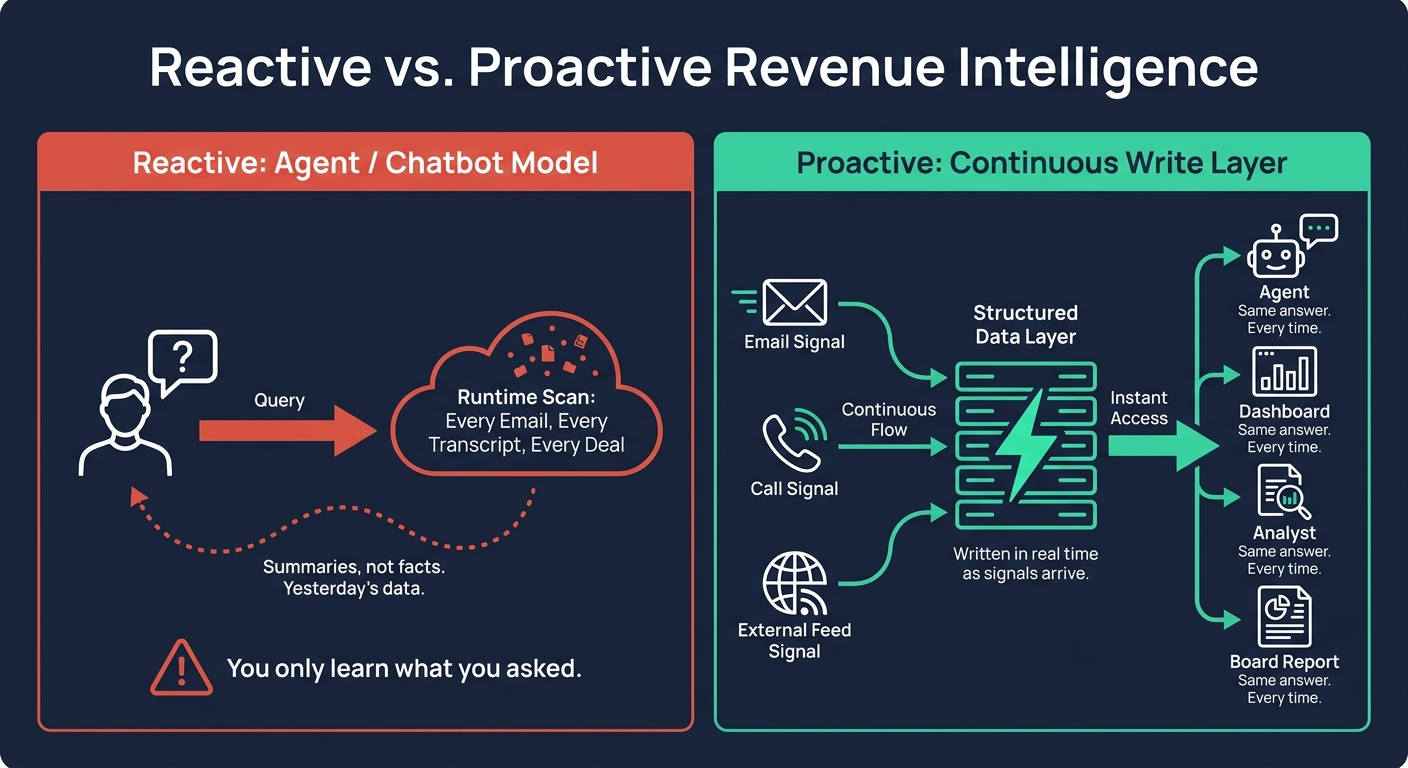
Reactive chatbot model vs. proactive continuous write layer, two architectures for revenue intelligence
How Structured Revenue Records Differ From What You Already Have
A CFO may ask: "We already have a CRM hygiene program, a data warehouse, and a revenue intelligence platform. Is this just that?"
No. Here is how structured, traceable revenue records differ from each:
CRM hygiene project. Hygiene cleans data after entry. It does not prevent bad values from entering in the first place, and it does not preserve the unstructured source for backfill.
Data warehouse and sync tools. A warehouse stores data and prepares it for analysis. It does not govern how that data was originally captured, and later logic changes can alter historical numbers. A source-backed revenue record keeps the original fact and logs changes instead of overwriting history.
Customer data platform. CDPs unify customer identity across marketing channels. They are designed for behavioral data, not typed revenue events with a traceable evidence chain.
Revenue intelligence platform. A tool that queries your CRM can only report the fields it reads. When records are written before any query runs, a later query reads a prepared fact instead of generating a new summary.
What Trusted, Reportable Revenue Data Looks Like
A finance-ready revenue record stores the value, the field type, the source, the timestamp, the actor, and the review status. That combination is what makes a record queryable by a human, an AI agent, or a board-ready dashboard and returns the same answer every time.
What a Structured Revenue Record Actually Contains
A typical opportunity record stores a deal name, an amount, a stage, and a close date. A finance-ready revenue record stores more than that. It stores how each value got there:
| Field | Example Value | Type | Source |
|---|---|---|---|
| Opportunity name | Enterprise Renewal | Text | CRM (rep-entered) |
| ARR | $148,000 | Currency | CRM (contract-verified) |
| Pipeline stage | Negotiation | Category | AI (email signal, 2026-06-12) |
| Close date | 2026-09-30 | Date | AI (champion confirmed via call, 2026-06-10) |
| Health score | 62 / 100 | Numeric | AI update, 2026-06-14 |
| Risk flag | Budget risk | Category | AI (budget concern raised in email, 2026-06-13) |
| Last signal | Budget declined via email | Text | Email thread ID #4471 |
| Signal timestamp | 2026-06-13 14:22 UTC | Datetime | System-written |
| Actor | AI pipeline monitor | System | Audit log |
| Confidence | 0.84 | Float | Model output |
| Human reviewed | No | Boolean | Pending review queue |
In CRM-only reporting workflows, finance may have to reconstruct source, timestamp, actor, and review status during review when those fields are not logged.
Controls on AI-Written Fields
AI-written fields require controls before finance can treat them as reportable. Without explicit governance, an AI writing to revenue records introduces a new category of risk: confident-sounding errors that no rep sanity-checked.
A working control layer has four components:
• Human review thresholds. Stage movements and close-date pushes above a materiality threshold (for example, any deal over $50K ARR) require rep or manager confirmation before the field is treated as final. Low-stakes updates, such as health score changes and engagement flags, can auto-commit.
• Confidence floor. AI-written fields below a set confidence score (for example, 0.70) are flagged for review rather than auto-committed, regardless of deal size.
• Override workflow. Any rep or manager can override an AI-written value. The override is logged with the actor, timestamp, and reason, so the change is auditable either way.
• Error remediation. When a field is later corrected, the original AI-written value and the correction are both retained in the audit log. The fact of the error, and who fixed it, is part of the record.
Writing AI signals to records when they arrive gives finance earlier visibility. Human review still handles material changes and low-confidence updates. A well-configured system flags exceptions for review rather than treating every AI write as final.
Write Signals to Records as They Arrive
When a budget concern surfaces in an email, the opportunity record should reflect it that day, not when a rep next logs in. When a competitor is mentioned on a call, it should land as a typed field, not get buried in a transcript nobody searches. Update the record close to when the signal arrives, whether the write is automated or rep-triggered.
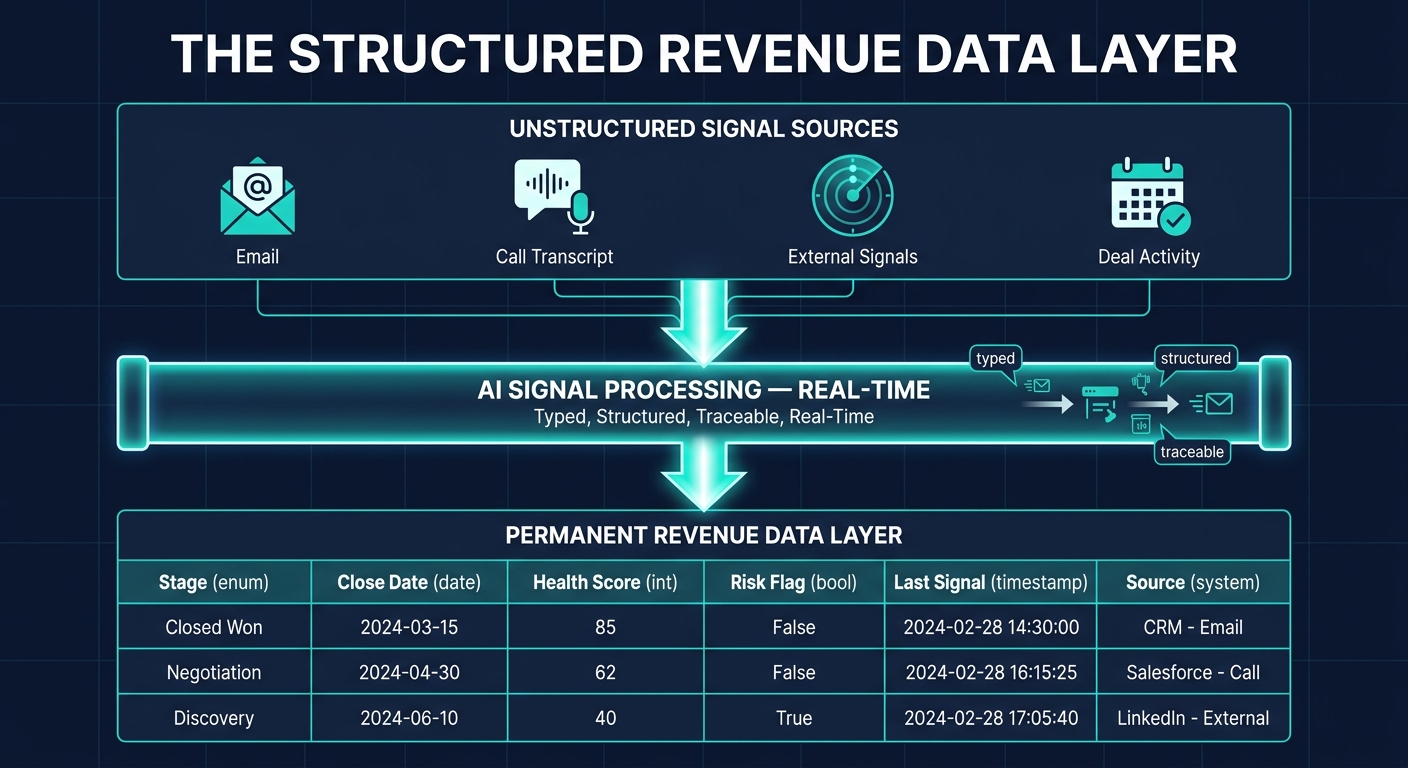
Unstructured signals from email, calls, and external sources written into structured revenue records
Because the source emails and transcripts are preserved, new structured fields can be added later and backfilled where the original emails and transcripts were retained and permissioned for reprocessing. Decide six months from now that you need a "competitor mentioned" field across every opportunity. The call transcripts and email threads are already in the system. If those transcripts and email threads were retained and permissioned for reprocessing, the system can parse them and populate the new field for the covered opportunities.
Separate Facts From Interpretations
A deal closing on March 31 is a fact. Whether it counts toward Q1 revenue depends on your recognition policy. Those are two different layers, and they should be stored and queried separately. When they are conflated, every downstream model becomes unreliable, because the policy and the fact are tangled in the same field.
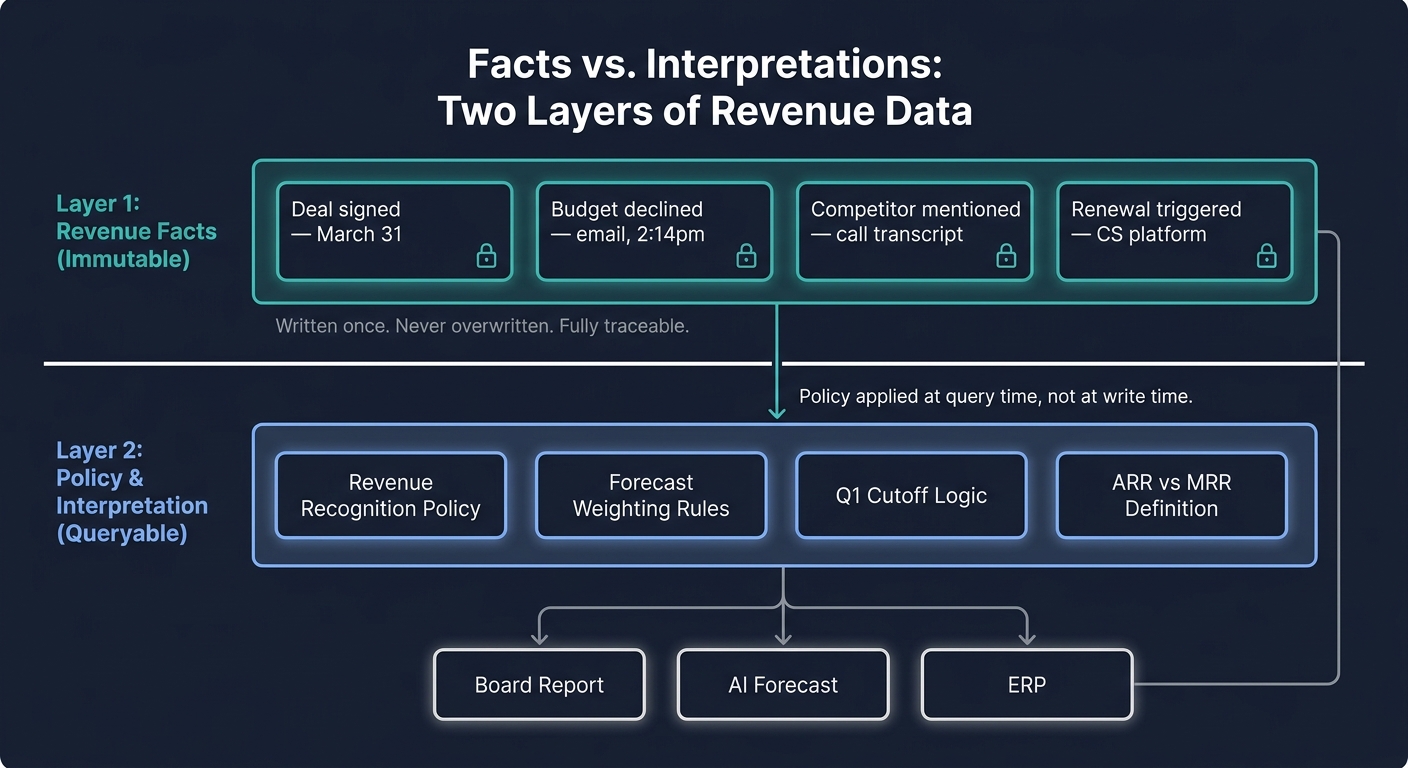
Two-layer revenue data architecture: immutable revenue facts on one layer, policy and recognition logic applied separately at query time
Before and After: What Changes for Finance
Before. A VP of Finance at a mid-market SaaS company prepares the monthly board pack. She pulls pipeline from the CRM, but three deals are missing close dates, two have amounts that differ from what is in the ERP, and one deal closed last week that the rep has not yet updated. She spends four hours reconciling, makes two calls to sales to verify numbers, and produces a report she describes as "our best estimate." The board asks why a deal slipped. Nobody has a traceable answer.
After the source-backed record is in place. The VP of Finance opens the board pack and reviews exceptions because deal amounts, close dates, and risk changes have already been written from the source signals. The deal that closed last week was written to the system within the same business day the contract was countersigned. She checks exceptions instead of rebuilding the report. When the board asks why a deal slipped, the answer is a three-line audit trail: budget concern flagged via email on the 13th, health score updated automatically, close date pushed to Q3 based on the rep's confirmed call.
The audit trail needs to exist before the board asks the question: source signal, timestamp, actor, and the field change it produced. Without that audit trail, finance has to ask the rep, check the spreadsheet, and explain the gap from memory.
CFO Audit Checklist: Is Your Revenue Data Actually Queryable?
Use this checklist against the fields finance uses in board reporting:
Field types and validation
- [ ] Is deal health stored as a numeric score with a defined calculation?
- [ ] Are risk factors recorded as fixed categories (budget risk, champion risk, competitive risk, timing risk), or does "at risk" mean whatever the last person who touched the record decided it meant?
- [ ] Are engagement signals, such as last activity, days since last response, and stakeholder count, stored as queryable fields?
- [ ] Are risk factors recorded as fixed categories (budget risk, champion risk, competitive risk, timing risk), or does "at risk" mean whatever the last person who touched the record decided it meant?
- [ ] Are engagement signals, such as last activity, days since last response, and stakeholder count, stored as queryable fields?
Source traceability
- [ ] When AI updates a health score or risk flag, is the triggering signal (the email, the call transcript, the external feed) recorded alongside the change?
- [ ] Can you distinguish between a field updated by a rep and one updated by an automated process, and see when each happened?
- [ ] Is there a timestamped log of every change to every revenue record, queryable by field, by date range, and by source system?
- [ ] Can you distinguish between a field updated by a rep and one updated by an automated process, and see when each happened?
- [ ] Is there a timestamped log of every change to every revenue record, queryable by field, by date range, and by source system?
Signal freshness
- [ ] Does your pipeline reflect signals from the last 24 hours, or the last time a rep logged in?
- [ ] Would a budget-declined email from this morning already appear as a risk flag on the relevant opportunity?
- [ ] Can a new structured field be added today and retroactively populated from historical source data?
- [ ] Would a budget-declined email from this morning already appear as a risk flag on the relevant opportunity?
- [ ] Can a new structured field be added today and retroactively populated from historical source data?
Queryable without manual reconstruction
- [ ] Can finance pull a board-ready pipeline report without a reconciliation step against the ERP?
- [ ] Can you answer "why did this deal slip?" from the record, including source signal, timestamp, actor, and field change?
- [ ] Can you answer "why did this deal slip?" from the record, including source signal, timestamp, actor, and field change?
If more than three answers are "no," treat AI outputs from those records as unapproved until each field can be traced to a source, timestamp, and owner.
What CFOs Should Be Asking Right Now
Before a CFO funds forecasting or compliance work in 2026, ask where each revenue value comes from, who changed it last, and which source supports it. That means auditing the logic between CRM and ERP, checking whether it is documented, versioned, and stable, and asking sales, marketing, and CS how revenue data is actually captured today, and whether any of it was ever objective to begin with.
How to Start: A Practical Implementation Path
A complete overhaul is not the right first move. Build the layer incrementally, starting where data quality failures are most expensive.
Week 1 to 2: Audit your most-used revenue fields. Pull the ten fields finance relies on most for board reporting (ARR, close date, pipeline stage, health, churn risk). For each field, document whether it is typed correctly, who can edit it, and whether changes are logged. Mark any finance-critical field that accepts free text, has no validation, or lacks a change log. Those are the starting points.
Week 3 to 4: Add field-level validation to the highest-risk fields. Start with close date, ARR, and pipeline stage. Require a date field for close date, a currency field for ARR, and an approved list for pipeline stage. Log every change with source, actor, and timestamp. This prevents text in date fields, ARR in the wrong format, and open-text pipeline stages that cannot be grouped or audited consistently.
Month 2: Instrument your signal sources. Connect the inboxes, call recording tools, and contract systems that generate revenue signals, then log each material signal with source, actor, and timestamp. Prioritize the signal source that creates the most manual work in your current process, and connect additional sources from there. All sources do not need to be connected on day one. A common one is a deal-stage change discussed over email but never reflected in the CRM.
Month 2–3: Define your typed risk and health schema. Decide what "at risk" means as a controlled vocabulary: budget risk, champion risk, timing risk, competitive risk. Decide how health is scored (numeric, 0–100). Document what triggers a change and who can override it. This is the schema work that makes every downstream report trustworthy.
Month 3 and beyond: Enable retroactive backfill. Preserve source emails, call transcripts, and contract records so new fields can be populated from historical evidence without asking reps to recreate the past. Start with a field finance already asks about during forecast review, such as competitor mentioned, budget risk, or next-step date. Each new field you define and backfill increases the queryability of your entire pipeline history.
A first useful layer, covering your top ten revenue fields with validation, logging, and signal-source connectivity, is achievable in eight to twelve weeks for most mid-market teams. The goal in the first quarter is not a complete system. The goal is that finance can answer "how do we know this?" for every field in the board pack.
Finance should be able to click a board-pack number and see the contract, email, CRM change, and timestamp that produced it.
About the Author

Robert Moseley IV is the Founder and CEO of GTM Engine, a pipeline execution platform that’s changing the way modern revenue teams work. With a background in sales leadership, product strategy, and data architecture, he’s spent more than 10 years helping fast-growing companies move away from manual processes and adopt smarter, scalable systems. At GTM Engine, Robert is building what he calls the go-to-market nervous system. It tracks every interaction, uses AI to enrich CRM data, and gives teams the real-time visibility they need to stay on track. His true north is simple. To take the guesswork out of sales and help revenue teams make decisions based on facts, not gut feel.






